
It has been a very long time – too long – since Search was disrupted. So it was only appropriate for the hype cycle to reach disproportionate levels with both Microsoft and Google embracing Large Language Models, namely ChatGPT and Bard, into their search experience. It should be noted that “experience” is the key word here, since LLMs have been part of the search backend for quite some time now, only behind the scenes.
By now, we’ve all heard the arguments against these chat-like responses as direct search results. The models are trained to return a single, well articulated piece of text, that pretends to provide an answer, not just a results list. Current models were trained to provide a confident response with lower emphasis on accuracy, which clearly shows when they are put to actual usage. Sure, it’s fun to get a random recipe idea, but getting the wrong information about a medical condition is a totally different story.
So we are likely to see more efforts invested in providing explainability and credibility, and in training the model to project the appropriate confidence vased on sources and domain. The end result may be an actual response for some queries, while for others more of a summary of “what’s out there”, but in all cases there will likely be a reference to the sources, letting the searcher decide whether they trust this reponse, or still need to drill into classic links to validate.
This begs the question then – is this truly a step function, versus what we already have today?

A week ago, I was on the hunt for a restaurant to go to, with a friend visiting from abroad. That friend had a very specific desire – to dine at a fish restaurant, that also serves hummus. Simple enough, isn’t it? Asking Google for “fish restaurants in tel aviv that also serve hummus” quickly showed how very much not so. Google simply failed to understand me. I got plenty of suggestions, some serving fish and some serving hummus, but no guarantee to serving both. I had to painstakingly go one by one and check them out, and most of them had either one or the other. I kept refining that query over and over, as my frustration kept growing.
With the hype still fresh on my mind, I headed over to ChatGPT:
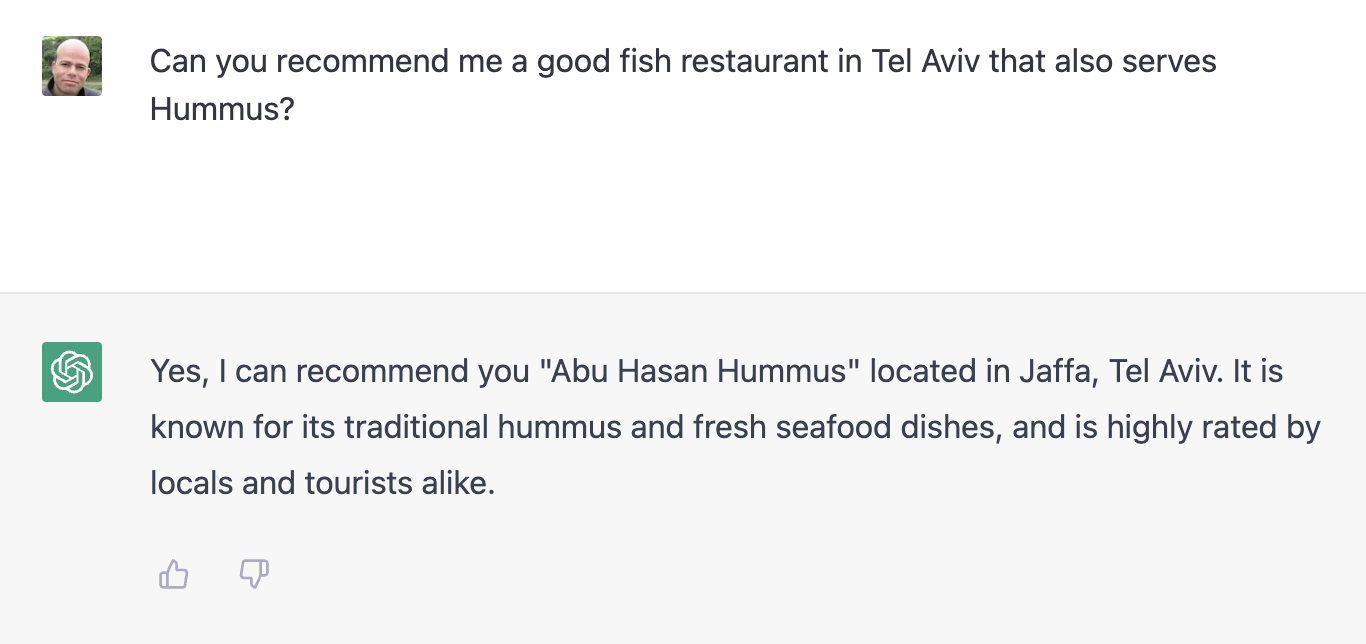
Great. That’s not much help, is it? I asked for a fish restaurant and got a hummus restauarant. For such lack of understanding, I could have stuck with Google. Let’s give it one last try before giving up…

That, right there, was my ‘Aha’ moment.
This result, and the validation it included, was precisely what I was looking for. ChatGPT’s ability to take both context pieces and combine them in a way that reflected back to me what information it is providing, totally made all the difference.
This difference is not obvious. Almost all of the examples in those launch events could do great also with keywords. Google’s Bard announcement post primary examples (beyond the “James Webb” fiasco) were “is the piano or guitar easier to learn, and how much practice does each need?” and “what are the best constellations to look for when stargazing?“. But take any of these as a regular Google queries, and you will get a decent result snippet from a trusted source, as well as a list of very relevant links. At least here you know where the answer is coming from, and can decide whether to trust it or not!

Left: Bard results from announcement post. Right: current Google results for the same query
In fact, Bing’s announcement post included better examples, ones that would work, but would not be optimal for classic search results, such as “My anniversary is coming up in September, help me plan a trip somewhere fun in Europe, leaving from London” (“leaving from London” is not handled well in a search query), or “Will the Ikea Klippan loveseat fit into my 2019 Honda Odyssey?” (plenty of related search results, but not for this exact ikea piece).
The strength of new language models is their ability to understand a much larger context. When Google started applying BERT into their query understanding, that was a significant step in the right direction, moving further away from what their VP Search described as “keyword-ese”, writing queries that are not natural, but that searchers imagine will convey the right meaning. A query he used there was “brazil traveler to usa need a visa” which previously gave results for US travelers to Brazil – perfect example for how looking only at keywords (or “Bag of Words” approach) would fail when not examining the entire context.

I am a veteran search user; I still am cognizant of these constraints when I formulate a search query. That is why I find myself puzzled when my younger daughter enters a free-form question into Google rather than translate it to carefully-selected keywords, as I do. Of course, that should be the natural interface, it just doesn’t work well enough. That is not just a technical limitation – human language is difficult. It is complex, ambiguous, and above all, highly dependent on context.
New language models can enable the query understanding modules in search engines to better understand these more complex intents. First, they will do a much better job at getting keywords context. Then, they will provide reflection; the restaurant example demonstrates how simply reflecting the intent back to the users, enabling them to validate that what they get is truly what they meant, goes a long way to help compensate for mistakes that NLP models will continue to make. And finally, the interactive nature, the ability to reformulate the query as a result of this reflection by simply commenting on what should change, will make the broken experience of today feel more like a natural part of a conversation. All of these will finally get us closer to that natural human interface, as the younger cohort of users so rightfully expects.




 Clusty.com’s
Clusty.com’s 






